

Ich habe kürzlich einen Wettbewerb von Kaggle versucht. Er war eigentlich eine der Aufgaben für einen Onlinekurs "Practical Predictive Analytics: Models and Methods". (Ich schreibe eine Rezension, nachdem ich den ganzen Kurs mache.)
Die Aufgabe für den Kurs ist ein Bericht von einem Kaggle-Wettbewerb: Man muss ein Vorhersagemodell erstellen und einen kurzen Bericht von dem Ergebnis vorlegen. Der Wettbewerb, den man versucht, ist nicht festgelegt. Ich habe "Titanic: Machine Learning from Disaster" ausgewählt, weil der Kursleiter ihn empfiehlt. Darüber hinaus hatte ich noch keinen Wettbewerb von Kaggle versucht, deshalb denke ich, dass mir der Wettbewerb passt, der für einen Anfänger von Kaggle ist.
Die Aufgabe von dem Wettbewerb ist ein Vorhersagemodell von den überlebenden Passagieren von Titanic. Die folgenden Daten sind gegeben: Klassen von einem Passagier (Pclass), Namen (Name), Geschlecht (Sex), Alter (Age), Anzähle von Ehepartnern (SibSp), Anzähle von Eltern/Kindern (Parch), Ticket Nummer (Ticket), Kabine (Cabin), der Hafen, an dem ein Passagier eingeschifft hat (Embarked). Sehen Sie bitte die Webseite, wenn sie die genaue Information wissen wollen.
Weil der Wettbewerb für einen Anfänger ist, gibt Kaggle schon drei Vorhersagemodelle. (Die Anzähle in den Klammern sind die Genauigkeit von den Vorhersagemodellen, nämlich Punkten.)
- Geschlechte-Modell (0.76555)
- Geschlechte-Klasse-Preis-Modell (0.77990)
- Random-Forest-Modell (0.77512)
Es ist einfach, das Geschlechte-Modell zu verstehen. Die folgende Kreuztabelle ist aus den Training-Daten gemacht.
| Not Survived | Survived | |
| female | 81 | 233 |
| male | 468 | 109 |
Das erste Vorhersagemodell sagt: Alle Frauen haben überlebt und alle Männer haben nicht überlebt. Dann ist die Genauigkeit des Modells für die Training-Daten 0.78676.
Das zweite Modell ist auch nicht schwierig zu verstehen. In der folgenden Tabelle stellt "Fclass" dar, wie viel der Passagiere für das Ticket ausgegeben hat. (1 = weniger als $10, ... , 4 = hoher als $30.) Die Spalte von "Survived" zeigt die Wahrscheinlichkeit vom Ãœberleben. "CountInTrain" ist die Anzahl der (überlebenden und nicht überlebenden) Leute in den Training-Daten. "CountInTest" ist die Anzahl der Leute in den Test-Daten.
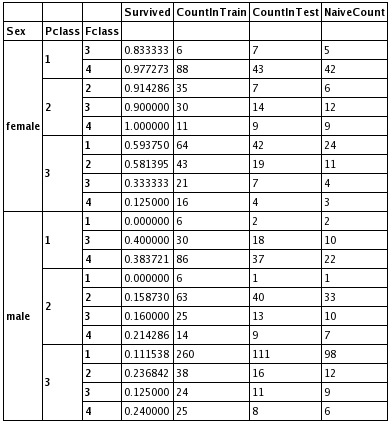
Das Geschlechte-Klasse-Preis-Modell sagt: Falls die Wahrscheinlichkeit der Klasse, zu der der Passagier gehört, gleich oder großer als 0.5, hat er überlebt. Zum Beispiel hat der Mann mit Pclass=1 und Fclass=3 nicht überlebt, weil die Wahrscheinlichkeit der Klasse, zu der er gehört, ist kleiner als 0.5.
"NaiveCount" ist die einfache Schätzung der Genauigkeit von dem Modell für jede Klasse in den Test-Daten. Deshalb ist die Schätzung der Genauigkeit des Modells gegeben durch sum(Naivecount)/sum(CountInTest) = 0.77990. Die Zahl ist gleich wie die Genauigkeit des Modells für die Test-Daten.
Das letzte Modell ist aus maschinellem Lernen gemacht: Man verwendet "Random Forest" für das Modell. Der Algorithmus ist bekannt für die hohe Genauigkeit und die geschätzte Genauigkeit durch Kreuzvalidierung ist rund 0.80936. (Weil "Random Forest" eine zufällige Zahl benutzt, ist das Ergebnis jedes Mal unterschiedlich.) Aber die Genauigkeit des Modells für die Test-Daten ist nur 0.77512. Sie ist sogar kleiner als die Genauigkeit von dem Geschlechte-Klasse-Preis-Modell!
A simple model is not always a bad model. Sometimes, concise, simple views of data reveal their true patterns and nature. (Getting Started With Random Forests)
Ja, das stimmt.
In dem nächsten Eintrag erzähle ich mein Ergebnis.