

Data Versioning
The reproducibility of a data science project is one of the most important aspects which must be satisfied. If you can not reproduce your result, then your result is worthless.
In the abstract level we can guarantee the reproducibility of a model by keeping the same data, the same algorithm (including data processing) and the same hyperparameters (including random seed).
data + algorithm + hyperparameters => model
It is not enough to manage source codes by git in order to manage algorithms and hyperparameters. We also have to manage the versions of data. Well, you push the data files on a git repository?
Consider two properties of data: "easy to compare" and "small (numbers of) files". If the data has both properties, then it is OK to push the file to a repository. Otherwise the file does not suit for a git repository. If it is not easy to compare two versions, then you have a trouble at merge. If the size is large or there are lots of data files, then it is hard to manage them one by one, and everything becomes slow.
Moreover we also have to take account into the triad of
(data, algorithm, hyperparameters) which produces the model:
data ---(data processing and algorithm with configuration)---> model
In order to reproduce the trained model, we need a right combination of versions of a data, an algorithm and configurations. We call it the coherence of the pipeline in this entry.
So we need a solution to the questions: coherence of the pipeline and data versioning.
I think that DVC is definitely one of the good solutions and I would like to introduce it in this entry.
Acknowledgement
I would like to thank Dmitry Petrov, Ivan Shcheklein and Ruslan Kuprieiev for comments to my question about DVC.
What is DVC
Disclaimer: I am not an expert of DVC. My explanation is not exactly correct and just small part of the whole features. Please consult documentation of DVC.
According to the official document
DVC is built to make ML models shareable and reproducible. It is designed to handle large files, data sets, machine learning models, and metrics as well as code.
Very roughly speaking, what DVC does is four-fold.
- Creates a corresponding file for each data file and manages the created file with git. (The same idea is employed by git-lfs and jupytext.)
- Changes data files according to the corresponding files.
- Provides interface to mange raw data on a remote storage.
- Tracks a chain between dependencies (data files and scripts) and outputs (data files and a model).
The first two features are for data versioning and the last one is for the coherence of a pipeline.
Use case: simple data-pipeline
Please read tutorial at first before reading this use case. My conclusion can be found at the end of this article.
Let's consider a simple use case. You will regularly receive some data (loading). Your job is to process the raw data (processing) and to construct a predictive model (modelling).

I wrote some scripts as a project skeleton sample codes. The ZIP file contains all files which are need to reproduce the use case.
0. Preparation
Environment
- Linux (OpenSUSE 15.0) (You need to modify some scripts on Windows.)
- Python 3.5 (Anaconda), requirements.txt
- DVC 0.35.7
If you use PyCharm, then you might also want to install plugins "BashSupport" and "Data Version Control (DVC) Support".
Git and DVC
Since DVC is based on git, we have to initialise git repository and then we initialise DVC.
> cd dvc-usecase-1.0
> git init
> dvc init
> git add .
> git commit -m "init"
1. Data Loading
01-loading-housing.py generates some data and stores it under
data/01-raw-data. The data which will be stored is our first data file to
manage with DVC.
One default option would be to use dvc add to the stored data in the same
manner as tutorial. But we have a script for data-loading. So we may execute
it through dvc run:
> dvc run -d 01-loading-housing.py \
> -o data/01-raw-data/housing.csv \
> -f run/01-loading-housing.dvc \
> --overwrite-dvcfile \
> python 01-loading-housing.py --round 1
This command executes the script and register the file
data/01-raw-data/housing.csv to DVC as a data file. We will explain the
reason of values of options later. The command which you
execute through dvc run (i.e. python ...) and the options of
dvc run are completely independent. This implies that you have to
manually specify relevant files through options (-d, -o and -f).
Therefore in my opinion it is better to use configuration file and write a small shell script. This ensures that the output file of the script will be registered to DVC as long as you use the value in the configuration file.
> bash run/01-loading-housing.sh
Note: If you are working on Windows, then you need to modify the script in a suitable way.
Then the following message is shown.
Running command:
python 01-loading-housing.py --round 1
Adding 'data/01-raw-data/housing.csv' to 'data/01-raw-data/.gitignore'.
Output 'data/01-loading-metrics.txt' doesn't use cache. Skipping saving.
Saving 'data/01-raw-data/housing.csv' to cache '.dvc/cache'.
Saving information to 'run/01-loading-housing.dvc'.
To track the changes with git run:
git add data/01-raw-data/.gitignore run/01-loading-housing.dvc
As the message says that the data file data/01-raw/housing.csv is
registered to DVC as a data file. This implies that the data file is
ignored by git and its version is managed by DVC.
But note that the command which is shown in the last line is incomplete.
The metric file run/01-loading-housing.dvc should also be added.
> git add .
> git commit -m "data loading round 1"
2. Data Processing
The second step is data processing: create a feature matrix (and split it
into a training set and a test set). The script
02-processing/nothing_except_splitting.py does the job. Well, it just
applies train_test_split to the raw data.
> bash run/02-processing.sh
> git add .
> git commit -m "data processing"
3. Data Modelling
The third step is modelling. We train an elastic net model, evaluate the model (RMSE) and store the trained model in a joblib format.
> bash run/03-modeling.sh
Do not forget to commit the result.
> git add .
> git commit -m "baseline model (elastic net)"
Point 1) Dependency chain and coherence of the pipeline
So far we just execute bash scripts (or dvc run commands) to train a
model. In our use case there are two points which are important for me.
One is a script as dependence. Recall that we need to manage the coherence of pipeline: a right combination of the versions of data, scripts and configurations. This can be achieved by chaining dependency of each processes:
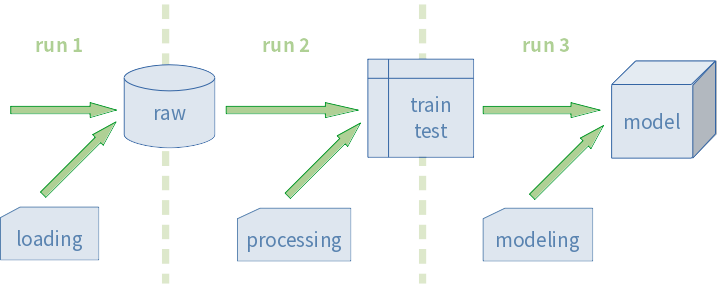
As we wrote, DVC is independent of the actual process. That is, DVC does not automatically create a dependence chain. You have to manually define it.
How should we define it? The point is dvc repro, which tracks a dependence
chain which is written in DVC files and reconstructs the chain
if there is any change in the files which are specified by -d option.
For reconstruction DVC executes the command which you executed through
dvc run commands:
python 01-loading-housing.py --round 1python 02-processing.py --test_size 0.4 --random_state 42python 03-modeling.py
These commands and options can not be modified. That is, any change related
to logic should be included in the files which the runs depend on.
dvc repro does not switch a script. If you want to switch an algorithm
you use, then the corresponding modification must be found in the file
which the corresponding run depends on.
Let us look at the dvc run command for the third step.
dvc run -d data/02-feature-matrix/training_data.csv \
-d data/02-feature-matrix/test_data.csv \
-d lib/modeling.py \
-o data/03-model/model.joblib \
-f run/03-modeling.dvc \
-M data/03-modeling-metrics.txt \
--overwrite-dvcfile \
python 03-modeling.py
The first two dependence files are data files. It is obvious that the
model and its evaluation depend on the data files. The third file
lib/modeling.py contains the algorithms which are going to be applied.
If we change the script, then dvc repro automatically detects the change
and executes the third run.
Because of the same reason dvc repro can detect any change of any
logic for runs.
- 1st run:
- logic for data loading:
01-loading-housing.py
- logic for data loading:
- 2nd run:
- Output of the 1st run:
data/01-raw-data/housing.csv - logic for data processing:
lib/processing.py
- Output of the 1st run:
- 3rd run:
- Output of the 2nd run:
data/02-feature-matrix/training_data.csv - Output of the 2nd run:
data/02-feature-matrix/test_data.csv - logic for modeling:
lib/modeling.py
- Output of the 2nd run:
If 01-loading-housing.py is changed, then the output file is also
changed, and this is the trigger of the 2nd run. The similar logic
implies that any change in lib/processing.py is a trigger of the
third run.
Note that any change in other scripts can not be a trigger.
Point 2) metric files
Another point is the existence of "metric file". You might have found
that each run has a metric file. (See -M option.) A metric file is
just a text file and you need to create it in your script.
The metric files which you specified in dvc run commands are registered
to DVC as a metric file and we can see the latest metrics in each branch.
> dvc metrics show -a
The output looks as follows:
master:
data/01-loading-metrics.txt:
user : stdiff
timestamp : 2019-05-06 23:22:39.683097+02:00
name : housing
housing_shape: 4091 x 9
data/03-modeling-metrics.txt:
user : stdiff
timestamp : 2019-05-07 22:50:29.678110+02:00
rmse_test : 0.5848106345079364
rmse_train : 0.5206126045907576
mean_rmse_validation: 0.5264851220449247
std_rmse_validation : 0.0505956677221194
model : StandardScaler|ElasticNet
best_params : {'enet__l1_ratio': 0.1, 'enet__alpha': 0.01}
data/02-processing-metrics.txt:
user : stdiff
timestamp : 2019-05-06 21:32:48.504695+00:00
name : nothing
train_shape: 2454 x 9
test_shape : 1637 x 9
This is pretty long, but you can check not only the performance metrics such RMSE, but also the data processing you did. (I don't know the reason of the wrong order.)
There are two reasons for metrics files (in particular for the 1st and 2nd runs).
- The metrics files explain the data pipeline.
- You can check the pipeline briefly and easily.
DVC files contain only MD5 checksums. Using it, you can easily check if there is any change in the files. But an MD5 checksum does not explain the file itself.
I strongly recommend deciding in advance what you log. I think it is better to write Metric class, such a class makes it easier to log the metrics in a consistent way.
4. Continue analysis
Random forest
Let us try another model
> git checkout -b randomforest
In lib/modeling.py we change two lines 32 and 33 as follows.
#pipeline, param_grid, name = elastic_net(**kwargs)
pipeline, param_grid, name = random_forest(**kwargs)
This change switches from the elastic net to the random forest. Then we
execute dvc repro command:
> dvc repro run/03-modeling.dvc
Stage 'run/01-loading-housing.dvc' didn't change.
Stage 'run/02-processing.dvc' didn't change.
WARNING: Dependency 'lib/modeling.py' of 'run/03-modeling.dvc' changed because it is 'modified'.
WARNING: Stage 'run/03-modeling.dvc' changed.
Reproducing 'run/03-modeling.dvc'
Running command:
python 03-modeling.py
Output 'data/03-modeling-metrics.txt' doesn't use cache. Skipping saving.
Saving 'data/03-model/model.joblib' to cache '.dvc/cache'.
Saving information to 'run/03-modeling.dvc'.
To track the changes with git run:
git add run/03-modeling.dvc
As you see, DVC detects the change in the script and execute the third run again. Now we commit the changes.
> git add .
> git commit -m "random forest"
Then dvc metrics shows -a shows the pipeline of the random forest
regressor.
You got a new data
It is time to get a new data. Before getting it, we should move to a new branch.
> git checkout master ## the modeling script trains elastic net
> dvc checkout ## you get back to the elastic net model (joblib)
> git checkout -b round2
Then you need to set round = 2 in config.ini. Then the first run
retrieves the new data.
> bash run/01-loading-housing.sh
You can check the result in data/01-loading-metrics.txt. Then we commit
the change
> git add .
> git commit -m "data loading round2"
and execute dvc repro.
> dvc repro run/03-modeling.dvc
This completes the dependency chain. You can check the whole pipeline
by looking at round2 section in the output of dvc metrics shows -a.
(Look at housing_shape and model. They must be "8223 x 9" and
"StandardScaler|ElasticNet" respectively.)
Q and A for the use case/project skeleton
Q. Why do not we write a code for training in 03-modeling.py?
If you want to do so, you can do so. A separate script makes it easy
to work with other colleagues: 03-modeling.py contains DVC-part and
the another script contains codes for training.
Q. Why did not we separate the script for data loading?
I will do so if I apply the skeleton to a real project. But then the dependence script is likely an SQL file. (Not a Python script.)
Q. Why is config.ini no dependency file?
This is not a configuration file which is meant in DVC tutorial. The INI file is just a list of references to the relevant file names and we use it to make "dvc run" commands consistent.
Pros and Cons
Pro 1) Independence from the codes
The programming language you chose does not matter. You can use DVC with R, Scala, Java, .....
Pro 2) It works everywhere
An installation package is provided for Windows, Mac OS and Linux. Moreover DVC can be installed via pip as a Python library. Therefore theoretically we can use DVC on Raspbian as well. (I have not check it, but DVC must work.)
Con 1) No status view
> git log --all --decorate --oneline --graph
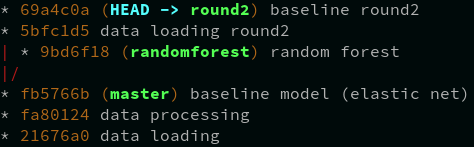
If you use git, it is easy to find where you are: HEAD. But how can I find the current state of the data files? How can I see all changes of the data files? which version of data we have on local.
The changes of data files which related to HEAD can be found by git log
command:
> git log --decorate --oneline --graph run/03-modeling.dvc
* 69a4c0a (HEAD -> round2) baseline round2
* fb5766b (master) baseline model (elastic net)
But this does not explain the files you have on local right now.
Best practice is: to execute dvc checkout any time.
Update data files and directories in workspace based on current DVC files.
Or you might want to execute dvc install in advance to ensure that
dvc checkout will always be executed just after checkout.
Con 2) No other applications have supported DVC yet
As far as I know there is no application supporting DVC. (for example
execute dvc repro, show/compare metrics files, detect inconsistent
data files, find commits with any change of data files, etc.) This
might be going to be solved by time.
Con 3) Careful design needed
DVC does not guarantee that your work can be reproducible. Instead you can use DVC to reproduce your work. To do so you have to define dependence files manually and you have to design them so that the pipeline will be reconstructed if there is any change in data, logic, algorithm and hyperparameters (including random seeds).
What if
- There is a dependence which is not listed in the dependence files.
- The list of dependence files is wrong.
Then your DVC file is completely useless.
Con 4) No monitoring
If your data science project lasts long and you have to train lots of models, then you definitely need to monitor the performance which the models achieved.
You might compare such models by using
dvc metrics show -a, but the command is awkward to compare 10 or
more models. Maybe the output of the command might be long. Each model
must have its own branch. This is not realistic.
For this purpose you need to use MLflow or something similar.
The biggest barrier
In my opinion DVC is a so great application that most of data scientists should introduce DVC to your projects. The cons which we saw above do not matter. Cons 1 and 2 are small things. Regarding Con 3 you have to be able to explain your pipeline anyway. You might want to use both MLflow and DVC if you need monitoring.
But I believe that many data scientists are not familiar with git. Or
even if they use git, what they do is only
git add, git commit and git push origin master --force.
Every data scientist must understand git? Well, if you think so, you do not understand data science at all. (cf. Question 1, Question 2) Data science is not a software development, it is data analysis. Large part of data science is occupied by BI tools and ad-hoc analysis.
That is, you often need only
- An BI tool (such as Tableau) and a connection to RDBMS, or
- A CSV file and a Notebook file (Jupyter/Rstudio).
In the first case git has no thing to do, because you can not merge two binary files. In the second case it is easy to keep the reproducibility because the data file is unchanged. Imagine that your have a business hypothesis to check, then you will do a small analysis first, not develop any software to implement it. The first analysis might be even enough. In such a situation there is no reason to use git.
Therefore, even though data scientists claim that they use git, it is often just a storage interface, there is only one branch or two. The only git commands which are needed are the three commands we mentioned above. Many data scientists do not understand git much, however DVC requires knowledge of git. Therefore DVC is often too much to introduce.
On the other hand, git is actually very useful for data science projects, especially several people work together: code review (especially difference of versions), code share, avoiding conflict of modifications, etc. Therefore I recommend learning git, if you have not learned it yet. (At least everyone needs to understand rebase and git flow.)
Then introduce DVC. It is worth trying DVC, even if you use only dvc install, dvc add and dvc remote/push/pull.
Summary
- DVC allows us to manage versions of data. You can also automate to reproduce your ML pipeline if you define the dependency chain of the pipeline by DVC.
- If you have a data science project which involves scripts, then it is worth introducing DVC, even if you use only the features for data versioning. ("dvc init/install/add/remote/push/pull")
- If you want to make use of the features for reproducibility, then you need to design the ML pipeline at first.
- It is assumed that all data scientists in the project understand git.