

In this entry I would like to write a small tip for Python programming.
Several months ago a colleague of mine said to me that
filter-map is faster than list comprehension.
This statement seems to be said often. In fact in Fluent Python you can find the following statement at page 25.
I used to believe that
mapandfilterwere faster than the equivalent listcomps
After the sentence the author mentions a counterexample.
Then which should we use? List comprehension or filter-map combination? What is the matter? I will explain one by one.
Warning
We will discuss only Python 3. More precisely we use an anaconda environment with Python 3.5.
Python2? It is already 2019.
Quick review of relevant Python's grammer
list comprehension
Python's list comprehension is a very useful syntax to create a new list from an old one.
before = [1, 2, 3, 4, 5]
after = [x**2 for x in before]
Then after is the list of squares of 1 to 5:
[1, 4, 9, 16, 25]. You can create the same list by
using for-loop.
after = []
for x in before:
after.append(x**2)
But the list comprehension is easier and clearer. Moreover you can also
create a restricted list by using the conditional statement if.
after = [x**2 for x in before if x % 2 == 1]
Then after is the list of the squares of 1, 3 and 5: [1, 9, 25].
NB: You can write if x % 2 instead of if x % 2 == 1 because
0 and 1 are evaluated as False and True, respectively.
map
map() is one of the built-in functions of Python. This takes a function
and a list (rigorously iterable object) and apply the function to each
element of the list.
def square(x):
return x**2
before = [1, 2, 3, 4, 5]
after = list(map(square, before))
Then after is [1, 4, 9, 16, 25] as before. But you have to apply list()
after map() to get the list because map() gives a generator rather than
a list.
Generator
If you have a list in your Python code, then all values of the list lie in the memory of your PC. This behaviour can cause a problem if you want to deal with a large list-like data.
A typical example is a large text data. Let us assume that you have a 100MB text file and you want to process the file line by line (e.g. word counts, line length, JSON lines, etc.).
lines = list(open("large_file.txt","r"))
Then lines is a list of lines in "large_file.txt". Thus the whole text
file is extracted in your memory. This is waste of the memory space.
NB: The actual memory space for the list of lines is pretty different from the file size. You can directly check it by using sys.getsizeof().
To avoid this problem the built-in function open() returns a generator.
A generator returns a value in a lazy way.
fo = open("large_file.txt","r")
Here fo is a generator which reads no lines until we need to read any.
Moreover we can read the file line by line through the generator:
for line in fo:
pass ## you can do something with `line`
Here the variable line contains only one line in the text file and
through for-loop we can read the file from head to toe without extracting
the whole text file in the memory.
As you have already understood, you can apply list() to a generator
to extract all values in the memory.
filter
filter() is also one of the built-in functions. This also takes a function
and a list (again, rigorously iterable object). The function is used as
a "condition" and filter() returns only the elements which satisfy the
condition.
def is_odd(x):
return x % 2 == 1
before = [1, 2, 3, 4, 5]
after = list(filter(is_odd, before))
Then after is [1, 3, 5]. Again, filter() returns a generator, not a
list. Therefore we have to apply list() to see all values which can be
generated.
list comprehension vs map-filter combination
Now you can understand that the list comprehension
lc = [x**2 for x in before if x % 2 == 1]
is equivalent to the following code.
def square(x):
return x**2
def is_odd(x):
return x % 2 == 1
mf = map(square, filter(is_odd, before))
Of course you can use anonymous functions (a.k.a. lambda expressions) instead of ordinary functions:
mf = map(lambda x: x**2, filter(lambda x: x % 2 == 1, before))
The difference of lc and mf is: lc is a list while mf is a generator.
list(mf) is exactly same as lc: Both are [1, 9, 25].
Recall the statement at the top of this entry.
filter-map is faster than list comprehension.
This means that list(mf) is faster than lc.
How faster is the former than the latter? It is easy to check, so why don't we check it?
Here is the whole code.
from time import time
def square(x):
return x**2
def check(x):
return x % 3 == 0
def listcomp_func_func(arr, n=10000):
start = time()
for _ in range(n):
sum([square(x) for x in arr if check(x)])
end = time()
print("listcomp func func : %.3f seconds" % (end - start))
def listcomp_lambda_lambda(arr, n=10000):
start = time()
for _ in range(n):
sum([x**2 for x in arr if x % 3 == 0])
end = time()
print("listcomp lambda lambda : %.3f seconds" % (end - start))
def map_filter_func_func(arr, n=10000):
start = time()
for _ in range(n):
sum(map(square, filter(check, arr)))
end = time()
print("map_filter func func : %.3f seconds" % (end - start))
def map_filter_lambda_lambda(arr, n=10000):
start = time()
for _ in range(n):
sum(map(lambda x:x**2, filter(lambda x: x % 3 == 0, arr)))
end = time()
print("map_filter lambda lambda : %.3f seconds" % (end - start))
if __name__ == "__main__":
lst = list(range(1000))
n = 10000
listcomp_func_func(lst,n)
listcomp_lambda_lambda(lst,n)
map_filter_func_func(lst,n)
map_filter_lambda_lambda(lst,n)
Because the original list before is too small, I take a large one lst
and I also change the condition slightly. I use sum() instead of list()
and apply sum() to the list comprehensions as well.
In __main__ we have four functions and all of them print the time which
is need to proceed the for-loop. In the for-loops we compute the same
sum 10000 times (default). The only difference is that we use a list
comprehension with or without ordinary functions or a map-filter
combination with or without ordinary functions.
listcomp_func_func(lst): list comprehension with ordinary functionslistcomp_lambda_lambda(lst): typical list comprehension (There is NO lambda expression. I know that. The name is just for an easier comparison.)map_filter_func_func(lst): map-filter combination with ordinary functions.map_filter_lambda_lambda(lst): map-filter combination with lambda expressions.
The result (on my PC) is following.
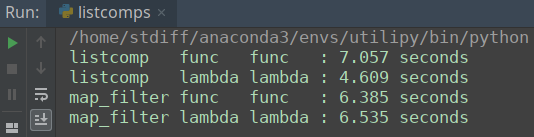
To be honest, I never expected this result. I believed that the list comprehension with functions is faster than the usual one. Anyway the result is quite different from what is often said.
We can obtain a similar result in a different way. We use -mtimeit
option and a generator range(1000) instead of the list and remove
sum():
> python -mtimeit -s'[x**2 for x in range(1000) if x % 3 == 0]'
10000000 loops, best of 3: 0.0585 usec per loop
> python -mtimeit -s'map(lambda x: x**2, filter(lambda x: x % 3 == 0, range(1000)))'
10000000 loops, best of 3: 0.0621 usec per loop
This shows that the map-filter combination with lambda expressions is slower than the equivalent list comprehension. But the difference is so small that you may get the converse evaluation sometimes. (Execute the same commands several times.)
Unfortunately I have no idea where the difference comes from. But I can summaries the result: There is no big difference between a list comprehension and a map-filter combination from the viewpoint of performance.
The performance has no priority!
You might be able to chose the best expression each time you need to convert a list to another. But then you forget one of the important things about programming.
The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.
Donald Knuth, Computer Programming as an Art, 1974
I agree that one should vectorize a for-loop if it is possible. This improves
the performance dramatically. But the use of map/filter does not improve
the performance in comparison with a list comprehension.
I believe that the simplicity of codes is most important. That is because the simplicity make it easy to check the logic and to maintenance the code. The readability belongs to the simplicity. So which is easier to understand? A list comprehension?
[x**2 for x in range(1000) if x % 3 == 0]
Or a map-filter combination?
map(lambda x: x**2, filter(lambda x: x % 3 == 0, range(1000)))
It is obvious that the former is clearer than the latter, isn't it? This is also true even though we use ordinary functions instead of lambda expressions:
[f(x) for x in lst if cond(x)]
is clearer than
map(f, filter(cond, lst))
because the former looks like an ordinary English sentence.
Of course there is a big difference: The former is a list and the latter is a generator. So you may use a map-filter combination to have a generator... Well, do you know there is a list-comprehension-like expression creating a generator?
(f(x) for x in lst if cond(x))
So why do you still use a map-filter combination?
Summary
- There is no big difference between a list comprehension and a map-filter combination from the viewpoint of performance.
- You should always use a list comprehension because of readability.
- When you need a generator you can use a list-comprehension-like expression.