

Ich bin Data Scientist von Beruf. Ich mache wirklich verschiedene Aufgaben: Ich entwickle in Python (oft in PySpark) eine Ingest Applikation. (Eine Applikation, die Rohdaten abholt und irgendwo (normalerweise im Data Lake) abspeichert.) Ich schreibe SQL- oder HQL-Skripts, um tabellarische Daten zu verarbeiten. Ich analysiere Daten mit/ohne maschinelles Lernen und Diagramme erstellen mit Python, R oder Qlikview. Ich gestalte auch neu ein ganzes Analyse-System und ein Daten-Modell.
Ich verstehe deshalb beide Perspektive: Software-Entwicklung und Daten-Analyse. Für die beiden Zwecke kann man Python benutzen. Aber die Denkarten sind unterschiedlich. Deswegen wird ein Software-Entwickler verrückt, wenn er Skripten sieht, die ein Data Scientist geschrieben hat.
On the other hand software engineers are quite reserved when it comes to machine learning. The whole concept is rather weird from their perspective, especially when the majority of so called models their data science team creates are short, hacky scripts with strange method calls and unreadable code in unfamiliar language. Where are all the design patterns? Where is the clean code? Where is logging or monitoring? Why is the code not reusable? Shouldn’t the code solving such a complex problem be more than two hundred lines long? It is a very ugly script that only one person can understand! Is it even programming anymore?
[Von But what is this “machine learning engineer†actually doing?]
Ja, die von Data Scientists geschriebenen (Python)-Skripten sind schlecht. Ohne Zweifel. Wie schlecht?
- Es gibt keinen Unit-Test.
- Nicht modularisierbar. Man kann das Skript für ein anderes Zweck nicht (sofort) verwenden.
- Warum denkst du, dass es einen Logger im Skript gibt?
- Da es kein Docstring gibt, muss man die ganze Definition einer Funktion lesen, um zu ermitteln, was für Daten die Funktion wirklich ergibt.
- Keine Klasse ist definiert, obwohl eine Klasse die Logik und das Skript viel einfacher macht.
- Ein Data Scientist versteht eigentlich die OOP gar nicht, auch wenn er oft Python-Codes zur Analyse schreibt und Objekte wie DataFrame benutzt.
- Er schreibt eine Funktion, um die global Variable zu ändern. Die Variable ist natürlich kein Input. (Ein Beispiel zeige ich unter.)
Es ist sehr einfach, solche Source-Code in Github zu finden. (Natürlich verlinke ich keine Repository...)
Kenntnisse von einem Data Scientist in Python
Es gibt zwei Sorten Gründe dafür, dass die Qualität des von einem Data Scientist geschriebenen Python-Codes schlecht ist: Die Fähigkeit eines Data Scientists und ein zu erreichendes Ziel in Data Science. Der erste Grunde ist einfach zu verstehen.
Ein Data Scientist ist kein Software-Entwickler. Auch wenn man Python für Data
Science und Software-Entwicklung verwenden kann, sind die zu lösenden Probleme
ganz anderes, deshalb sind die Denkarten auch anderes. Darüber hinaus benutzt
ein Data Scientist einfach die bekannten Bibliotheken (wie pandas oder
sklearn) und er gestaltet keine Bibliothek. Es gibt sogar kaum Gelegenheit,
eine Klasse zu definieren.
Meine Kenntnisse der OOP ist auch begrenzt. Am 19.02.2017 habe ich einen Online-Test für einen fortgeschrittenen (mid-level) Python-Entwickler gemacht. Das Ergebnis ist folgend.
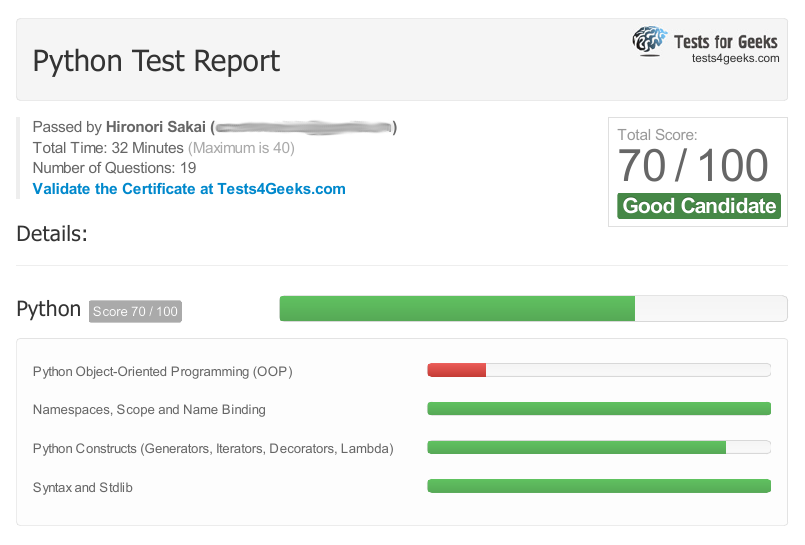
Das Ergebnis von OOP ist deutlich schlecht. Deshalb habe ich nach dem Test Effective Python gelesen, um meine Kenntnisse zu verbessern.
Für jeden Fall würde ich sagen, dass der Test für einen fortgeschrittenen war. Deswegen waren die Probleme nur Python-spezifisch. Also es ging nicht um die allgemeinen Kenntnisse der OOP.
Ein Beispiel
Aber egal. Es gibt keinen Zweifel daran, dass Data Scientists nicht gut Python kennen. Genauer gesagt, dass sie kaum wissen, wie Python-Codes geschrieben werden sollten. Deshalb schreiben sie beispielsweise ein Code wie folgend.
data = []
def get_data(n):
r = requests.get("http://api.example.com/data?page=%d" % n)
data.append(r.json())
get_data(10)
Eine Funktion schreiben, um die globale Variable zu ändern. Das Code funktioniert wie erwartet. Ein funktionierendes Code ist genug, oder? (Das Code wurde eine (relativ) bekannte Bloggerin geschrieben. In Jupyter Notebook. Natürlich habe ich die Variablen usw. geändert.)
Das Code hat zwei Probleme:
- Die Funktion beeinflusst den Zustand außerhalb der Funktion.
Wer kann sofort finden, dass
get_data(10)den Zustand der Variabledataändert? - Die Funktion ist nicht modularisierbar. Deshalb ist es nicht möglich, die Funktion außerhalb des Skripts zu testen.
Für den zweiten Punkt gibt es hier zwei Skripten.
main.py
data = []
def get_data(n):
print("id(data) in get_data: ", id(data))
data.append(n)
if __name__ == "__main__":
get_data(3)
print(data)
from_outside.py
from main import get_data
data = []
get_data(4)
print("id(data) in from_outside.py:", id(data))
print(data)
Das Ergebnis von print(data) in from_outside.py ist [], nicht
[4]. Der Grund kann man sofort finden, wenn man das Skript ausführt.
(Wenn man auch die globale Variable data importiert und sie statt data
zu initialisieren benutzt, erzeugt from_outside.py [4].)
Es gibt einige Lösungen.
- Die globale Variable als Input geben. Dann kann man sofort verstehen,
dass die Funktion mit der Variable
dataverbunden ist. - Die abgeholten Daten als Output geben. Dann kann man durch
data.append(get_data(3))die globale Variable richtig ändern. - Eine Klasse definieren. Ein Instanz der Klasse behält beispielsweise die abgeholten Daten und eine Methode, die durch API die Daten abholt.
- Ohne Funktion. Das originales Notebook hat nur ca 30 Zeilen und die Funktion wird nur einmal aufgerufen. Warum braucht man die Funktion überhaupt?
Übrigens wollten Sie vielleicht etwas über den Endpoint sagen. Aber das ist eine andere Geschichte.
Anderer Grund: Data Science ist keine Software-Entwicklung
Auch wenn man in beiden Bereichen Python verwenden kann, sind die Denkarten unterschiedlich, wie ich oben geschrieben habe. Ein zu erreichendes Ziel ist auch anderes.
Zum Beispiel: ad hoc Analyse. Das ist ein typischer Typ der Aufgaben.
Ich schreibe ein Skript zum Testen auf jeden Fall. Aber keinen Unit-Test schreibe ich, es sei denn, dass er verlangt wird. Das liegt daran, dass der Unit-Test nur sinnvoll ist, wenn die Applikation weiter entwickelt wird. Aber diese Anfrage ist nur einmalig. Deshalb "ad hoc".
Der Unit-Test ist wichtig, weil die Implementation später automatisch getestet werden kann. Nach der Witerentwicklung kann man durch den Unit-Test überprüfen, ob seine Implementation eine alte Funktion nicht kaputt macht. Mit anderen Worten macht der Unit-Test kein Sinn, wenn er später niemals ausgeführt wird. Wenn man sich entscheidet, das Skript im produktiven System zu integrieren, sollte man einen Unit-Test schreiben.
(Übrigens benutze ich einen Logger, wenn ich eine PySpark-Applikation automatisch eine KPI berechnen lasse, so dass ich den Zustand der vorgelegten Applikation und das Performance später überprüfen kann.)
Oder angenommen, dass die Aufgabe eine prediktive Analyse. Sie haben die Daten für die Preise von Häusern. Ihr Aufgabe ist, ein Vohersagemodell für den Preis zu erstellen.
Sie starten Jupyter Notebook und erstellen ein Notebook. Sie importieren die Daten und machen sie sauber. Sie verarbeiten die Daten, sodass Sie ein maschinelles Lernen für die Daten verwenden kann. Sie erstellen mehrere Diagramme, um die Daten zu verstehen. Sie versuchen, einige Modelle zu trainieren und durch 5-fold Cross-Validation die Hyperparameter zu optimieren. Sie bewerten die trainierten Modelle und währen das beste Modell aus.
Sollte man einen Unit-Test für diese Analyse schreiben? Was für einen Test? Warum braucht man einen Logger für die Analyse?
Natürlich nicht.
Also Analyse enthält keinen Unit-Test, keinen Logger eigenen Klasse oder keine Erstellung einer Bibliothek. Das ist ganz normal.
Brücke zwischen Software-Entwicklung und Data Science
Also die Qualität eines von einem Data Scientist geschriebenen (Python-)Skripts ist schlecht, weil Sie die Skripten aus der Perspektive von Software-Entwicklung bewerten. Was in der Software-Entwicklung wichtig ist, ist nicht unbedingt wichtig in Data Science. Aber das Modell, das ein Data Scientist trainiert hat, kann in einem produktiven System integriert werden.
Die Integration klingt "Anpassung des von Data Scientist geschriebenen Codes an die Software-Entwicklung". Das ist richtig. Aber die Integration eines mathematischen Modell ist auch anderes als eine "normale" Software-Entwicklung. Man muss beispielsweise die folgenden Punkte überlegen.
- Ist das trainierte Modell schnell genug für ein Live-System?
- Gibt es genug Ressourcen, um das Modell zu verwenden?
- Lässt das Modell regelmäßig aktualisieren? Online-Learning oder neu es trainieren? Wie lässt sich das neu trainierte Modell validieren?
- Wie bewertet man das laufende Modell? A/B-Test?
- Wie bekommt das Modell das Input?
- Wie zeigt das Modell das Output?
Was muss man implementieren/beachten soll, ist abhängig von dem System und der Strategie.
Um ein mathematisches Modell im System umzusetzen, ist die Zusammenarbeiten von Data Scientists und Entwicklern wichtig, und vor allem ist eine Person nötig, die sowohl Data Science als auch Software-Entwicklung kennt.
Im Blog-Eintrag, den ich am Anfang verlinkt habe, nennt man eine solche Person "machine learning engineerâ€.
Zusammenfassung
Die Qualität der von Data Scientist geschriebenen Codes ist schlecht, wenn man sie aus der Software-Entwicklung-Perspektive bewertet. Das liegt daran, dass Data Science anderes als Software-Entwicklung ist.
- Eine Analyse verlangt keinen Logger, keinen Unit-Test, usw. Deshalb scheint ein Skript für eine Analyse nicht komplett.
- Eine Analyse verlangt keine komplexe Programmierung, deshalb sind die Kenntnisse von Data Scientists in Python (bzw. Software-Entwicklung) begrenzt.
Aber auch wenn Data Science keine Software-Entwicklung ist, ist eine Person, die sowohl Data Science und Software-Entwicklung kennt, nötig, um ein trainiertes Modell im System umzusetzen.