

Ich habe kürzlich die Serie "Data Science at Scale" fast gemacht. Also den letzten Kurs (Capstone project) versuche ich nicht. In diesem Eintrag würde ich über die Serie schreiben.
Die Serie besteht aus vier Kurse.
- Data Manipulation at Scale: Systems and Algorithms (4 Wochen)
- Practical Predictive Analytics: Models and Methods (4 Wochen)
- Communicating Data Science Results (3 Wochen)
- Data Science at Scale - Capstone Project
Um sich bei dem Capstone-Projekt anzumelden, muss man die Kursgebühr bezahlen (und die anderen Kurse mit Verifizierung bestehen). Deshalb melde ich mich nicht bei dem letzten Kurs an. Diese Kurse sind sehr praktisch und ich denke, dass es sich lohnt, die Kursgebühr zu bezahlen, um sich bei dem Projekt anzumelden. (Ich dürfte das Projekt machen, falls ich genug Zeit habe.)
Der Grund, warum ich die Kurse gemacht habe
Es ist einfach, einen Algorithmus von maschinellem Lernen auf einem PC auszuführen. Aber es ist schwer, Massendaten zu verwalten. Massendaten ist einen der wichtigen Aspekte von Data-Science, deshalb wollte ich lernen, wie man Massendaten manipulieren.
Die Serie war die einzige Serie, in der man kostenlos die Grundlage von Massendaten zu lernen. (Jetzt kann man kostenlos die Grundlage von Hadoop in der Serie "Big Data" lernen. Die mache ich.)
Praktische Aufgaben
Viele Onlinekurse für Data Science verlangen keine Kenntnisse auf einer Programmiersprache. Aber die Serie ist anderes. Ich bin der Meinung, dass man mindestens sowohl Python als auch R gut kennen sollte, um die Kurse zu bestehen. Dazu sollt man im Voraus maschinelles Lernen lernen. (Der Kurs von Prof. Ng oder ISLR ist eine gute Auswahl.)
What background knowledge is necessary?
Learners will need intermediate programming experience (roughly equivalent to two college courses) and some familiarity with databases. Programming assignments throughout the Specialization will use a combination of Python, SQL, Scala, R, and Javascript; familiarity with one or more of these languages will be helpful.
Dank der Annahme sind die Aufgaben sehr praktisch. Zum Beispiel: ein Bericht der Erfahrung von Kaggle-Wettbewerb, Graphanalyse von Massendaten auf AWS durch Apache Pig, usw. Darüber hinaus kann ein Teilnehmer die Berichte von anderen Teilnehmern für Peer-Review lesen. Das war gute Erfahrung.
Theoretischer Unterricht
Der Unterricht ist meistens theoretisch. Zum Beispiel: Relationale Algebra. Wer SQL lernen wollte, muss die relationale Algebra nicht verstehen. Aber im Kurs ist die relationale Algebra eine Grundlage von Datenbanken. Bis ich den Kurs gemacht habe, habe ich SQL Befehle nur als einfache Befehle betrachtet. Deshalb finde ich den Unterricht sehr nützlich und interessant.
Die Serie (außer des Projektes)
Unter diesem Github-Konto kann man die Aufgaben in der Serie finden.
1. Data Manipulation at Scale: Systems and Algorithms.
Das Thema ist Datenbanken: RDBMS, MapReduce, noSQL. Das ist was ich verstehen wollte und eine der besten Einführung von Datenbanken (sogar Massendaten). Man lernt auch Apache Pig und Graphanalyse. Diese übt man im dritten Kurs.
Aufgaben
- Twitter Sentiment Analysis (Python): Warm-up
- SQL for Data Science (SQL): Die Grundlage von der relationalen Algebra und SQL (und Matrizenmultiplikation).
- Thinking MapReduce (Python): Die Aufgabe, um die Idee von MapReduce (ohne Hadoop) zu verstehen. Man schreibt Map- und Reduce-Funktionen.
2. Practical Predictive Analytics: Models and Methods
Maschinelles Lernen ist das Thema. Aber wie ich oben gesagt habe, sollte man im Voraus maschinelles Lernen lernen. Der Kursleiter erklärt kurz Algorithmen.
Aufgaben
- R Assignment: Classification of Ocean Microbes (R): Für die Aufgabe sollte man im Voraus R lernen. Ein bisschen kompliziert.
- Kaggle Competition Peer Review (Irgendeine Programmiersprache): An einem Kaggle-Wettbewerb teilnehmen und einen Bericht über die Erfahrung schreiben.
3. Communicating Data Science Results
Im Kurs geht es um Visualisierung, Privatsphäre, Reproduzierbarkeit und Cloud Computing.
Aufgaben
- Crime Analytics: Visualisation of Incident Reports (Irgendeine Programmiersprache): Visualisierung von verschiedenen Statistiken (ohne maschinelles Lernen).
- Graph Analysis in the cloud: Quelltexte auf Pig Latin schreiben und die Quelltexte auf AWS ausführen. Für die letzte Aufgabe manipuliert man 500 GB Massendaten.
Schlechte Punkte der Serie
Ich habe mehr Mal die Serie gelobt, aber natürlich gibt es Probleme der Serie.
Lärm in der Videos
Mehrere Videos haben unangenehmen Lärm, sodass der Lärm einem beim Lernen stört.
Viele veraltete Beschreibungen, keine Aktualisierung
Weil der Link falsch ist, kann ein Teilnehmer die richtige Aufgabe nicht erreichen. Ein Teilnehmer hat im Forum gebeten, einen richtigen Link zu geben. Aber der Kursleiter hat endlich keine Antwort geschrieben. Also niemand kümmert sich um den Kurs.
In order to complete this assignment, you will need to make use of Amazon Web Services (AWS). Amazon has generously offered to provide up to $50 in free AWS credit to each learner in this course to allow you to complete the assignment.
Vorher habe ich keine Nachricht dafür. Man kann sich kostenlos bei dem Kurs anmelden, aber man muss die Gebühr von AWS bezahlen.
Fazit
Ich bin der Meinung, dass es sich lohnt, die Serie zu machen. Insbesondere ist der erste Teil wunderbar. Wer sich für Massendaten interessiert, sollte auch den dritten Teil machen.
Zusatz
Das Histogramm von einem Graph ist das Streudiagramm von Punkten $(d, n(d))$ ($n=1,2,3,\cdots$). Hierbei ist $n(d)$ die Anzahl von Knoten mit $d$ outgoing Kanten.
Die letzte Aufgabe ist nicht das Histogramm von einem Graph, sondern die Anzahl der Punkten von dem Histogramm. Weil ich ein Histogramm von einem Graph gelernt habe, habe ich auch mit dem Histogramm von dem großen Graph gerechnet.
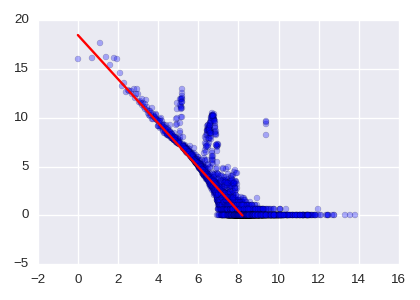
Falls man genau die Punkte auf diesem Bild zählt, ist die Zahl die richtige Lösung der letzten Aufgabe!
Das Streudiagramm wird mit log-log scale gezeigt. Es wird oft gesagt, dass das Histogramm von einen naturalen großen Graph als eine Linie beobachtet wird. Die rote Linie auf dem Bild ist die Linie. Diesmal erhalten wir die folgende Formel.
$$n(d) = \frac{e^{18.5}}{d^{2.2561}}.$$
Ich soll sagen, dass man die rote Linie nicht durch liniere Regression (mit oder ohne Regularisierung) bekommen kann.